Partitioned Primary Index (PPI) is one of the powerful feature of Teradata which allows a user to access a part of the table rather than full table access. This helps in improving the performance as full table scan is eliminated. PPI works same as Primary Index for the data distribution, but creates partitions according to range or case as specified in the table.
There are 4 types of PPI:
- Case partitioning.
- Range based partitioning.
- Multi-level partitioning.
- Character based partitioning.
Let us take one example of product table(a part of table is taken here) and try to understand all the above methods of portioning a table: 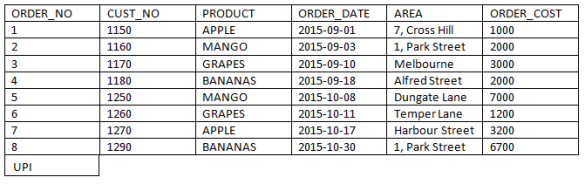 You run the below query:
You run the below query:
SEL * FROM DB.PRODUCT_TABLE WHERE ORDER_DATE = '2015-10-30';
Explain plan for this will look something like this:

Now when the data is distributed, the data will look something like this. In this case rows will be sorted in each AMP based on row-id. 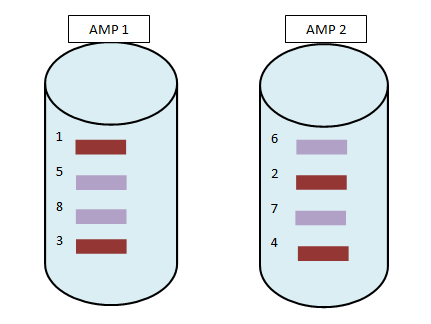 This will lead to full table scan. To avoid this we can use partition primary index.
This will lead to full table scan. To avoid this we can use partition primary index.
RANGE PARTITIONING:-
CREATE TABLE PRODUCT_TABLE (
ORDER_NO INTEGER NOT NULL,
CUST_NO INTERGER,
PRODUCT VARCHAR(20),
ORDER_DATE DATE,
AREA VARCHAR(50),
ORDER_COSTDECIMAL(10,2) )
PRIMARY INDEX(ORDER_NO)
PARTITION BY RANGE_N (ORDER_DATE BETWEEN DATE '2015-01-01'
AND DATE '2015-12-31' EACH INTERVAL '7' DAY);
When we create a table using this, the distribution will be something like below: 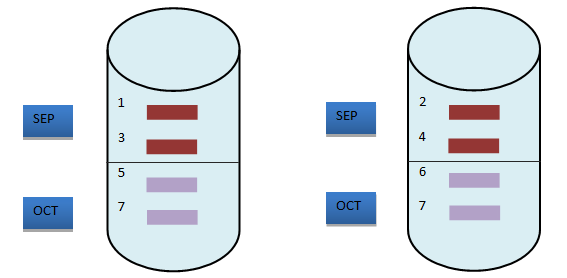 As we can see from above that now the rows have been partitioned according to the ORDER_DATE The explain plan will look like:
As we can see from above that now the rows have been partitioned according to the ORDER_DATE The explain plan will look like: 
Now from the above explain plan we can see that the data retrieval is taking less time and not going for full table scan, hence will improve the performance of the query.
CASE PARTITIONING:-
CREATE TABLE PRODUCT_TABLE
(
ORDER_NO INTEGER NOT NULL,
CUST_NO INTERGER,
PRODUCT VARCHAR(20),
ORDER_DATE DATE,
AREA VARCHAR(50),
ORDER_COSTDECIMAL(10,2)
)
PRIMARY INDEX(ORDER_NO)
PARTITION BY CASE_N(ORDER_COST< 1000,
ORDER_ COST< 2000,
ORDER_ COST< 5000,
NO CASE, UNKNOWN);
The NO CASE condition is applied for the values which do not fulfill the case criteria and UNKNOWN for NULL values if any. This will work same as range partitioning only the difference would be in the partitioning value. Here the data will be partitioned according to the ORDER_COST.
MULTILEVEL PARTITIONING:-
The maximum number of partitions you can define is 65,535.
CREATE TABLE PRODUCT_TABLE
(
ORDER_NO INTEGER NOT NULL,
CUST_NO INTERGER,
PRODUCT VARCHAR(20),
ORDER_DATE DATE,
AREA VARCHAR(50),
ORDER_COSTDECIMAL(10,2)
)
PRIMARY INDEX(ORDER_NO)
PARTITION BY (RANGE_N(ORDER_DATE BETWEEN DATE '2015-01-01' AND DATE '2015-12-31'
EACH INTERVAL '1' DAY)
CASE_N (ORDER_TOTAL < 1000,
ORDER_TOTAL < 2000,
ORDER_TOTAL < 3000,
NO CASE, UNKNOWN));
Character based partitioning:-
CREATE TABLE EMPLOYEE (
EMP_ID INTEGER,
LAST_NAME VARCHAR (30) CHARACTER,
FIRST_NAME VARCHAR(30),
CITY VARCHAR(50))
PRIMARY INDEX (EMP_ID)
PARTITION BY CASE_N (LAST_NAME LIKE 'A%', LAST_NAME LIKE 'B%',
LAST_NAME LIKE 'C%', LAST_NAME LIKE 'D%',
LAST_NAME LIKE 'E%', LAST_NAME LIKE 'F%',
LAST_NAME LIKE 'G%', LAST_NAME LIKE 'H%',
LAST_NAME LIKE 'I%', LAST_NAME LIKE 'J%',
LAST_NAME LIKE 'K%', LAST_NAME LIKE 'L%',
LAST_NAME LIKE 'M%', LAST_NAME LIKE 'N%',
LAST_NAME LIKE 'O%', LAST_NAME LIKE 'P%',
LAST_NAME LIKE 'Q%', LAST_NAME LIKE 'R%',
LAST_NAME LIKE 'S%', LAST_NAME LIKE 'T%',
LAST_NAME LIKE 'U%', LAST_NAME LIKE 'V%',
LAST_NAME LIKE 'W%', LAST_NAME LIKE 'X%',
LAST_NAME LIKE 'Y%', LAST_NAME LIKE 'Z%',
NO CASE, UNKNOWN);
The above example will thus create partitions based on the last name.
Advantages of PPI:-
- It avoids full table scan and only relevant part of table is scanned.
- Fast insert, delete operations.
- Can be created on global temp table, volatile table, non-compressed join indexes.
- For range based queries we can remove SIs and use PPI, which will reduce space of an overhead SI subtable.
Disadvantages of PPI:-
- An additional of 2 bytes is added to each row and hence increases the perm space.
- While joining a PPI table with non-partitioned table make take long time.
- Access other than the PPI column may take more time.