RAID is a technology that uses multiple physical disk drives to protect data from a single disk failure.
The purpose of RAID is to ensure that at the time of failure, there should be one copy of data which should be available for immediate use. In some cases the Teradata systems are pre-configured with RAID 1. Before we learn about RAID 1 and how it works, let’s understand the types of RAIDs.
RAID 0:-
RAID 0 consists of striping (dividing data into blocks), without mirroring (duplicate) or parity (backup). The data blocks are stripped into different blocks and stored on different disks. This result into assured read/write operations on multiple disk and thus improves the performance as Teradata can access the data parallel.
For RAID 0 at least 2 disks are compulsory.
Below diagram shows how the block gets distributed: 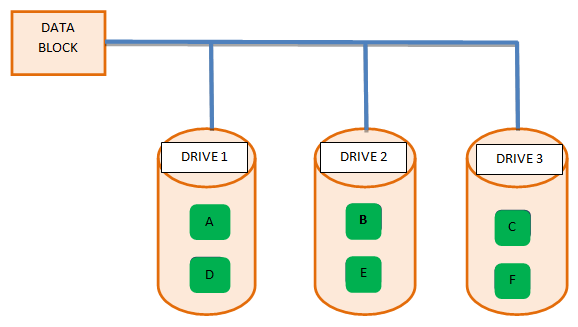
When any data come from the AMP the data is divided into blocks such as A, B, C, D, E, F. Now these data blocks go to different disks, as shown in diagram. Only 1 copy of data block is available, hence RAID 0 is not recommended for critical systems.
Advantages
- RAID 0 offers great performance, both in read and writes operations. There is no overhead caused by parity control.
- All storage capacity is used, there is no overhead.
- The technology is easy to implement.
Disadvantages
- RAID 0 is not fault-tolerant. If one drive fails, all data in the RAID 0 array are lost. It should not be used for critical systems.
- Should only be used for data that changes infrequently and is backed up regularly.
RAID 1 (Mirroring):-
RAID 1 consists of duplicating the data block on two drives. It should be used for very critical data only, as the space requirement increases due to data been stored twice on the disk.
Following diagram depicts the data storage in RAID 1 technique:
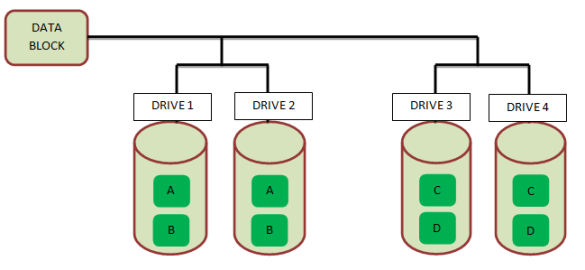
We can see that every block (A, B, C, D) is duplicated in different disk drive. You need at least 2 drives to implement RAID 1. By default Teradata implements this technique.
Advantages:
- It is a very simple technology and efficient too.
- If any failure occurs the access to data does not get affected, as copy of data is available.
- It offers good speed at read/write as compared to single disk operation.
Disadvantages:
- The main disadvantage is that storage space increases as data is duplicated and stored twice.
RAID 5:-
This level is based on striping with parity. Parity is the computation in which the data from 2 drives is stored together on the third one as a backup.
The same technique is used in RAID 5 technique.
Let us understand the concept with some diagram.
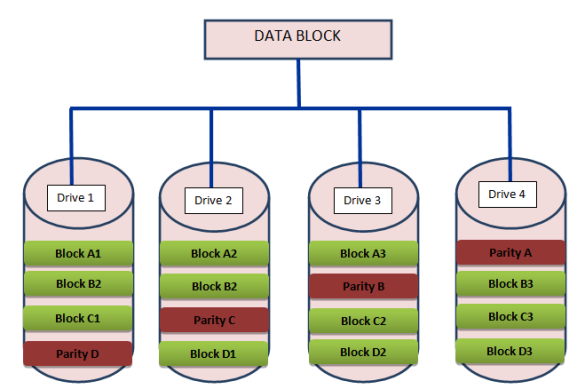
As we can see from the above diagram, the data is striped into 3 blocks. Each block is placed on different disks and the backup of all is stored on some other disk. Thus, for all the data in Block A1, A2, A3 a Parity A is maintained which can be used at the time of failure in any of the drives.
Thus it helps in restoring the data back at the time of fault.
Advantages:
- Read operations are very fast.
- Even if any of the drives fails, you still can access the whole data from the parity.