A Secondary Index(SI) offers an alternative path to access the data. Unlike Primary Index which can only be defined at the time of table creation, a Secondary Index can be create/drop after the creation of the table also. There are two types of Secondary Index:
- Unique Secondary Index (USI).
- Non-Unique Secondary Index (NUSI).
As soon as you define secondary index, the next move comes from Teradata creating a Subtable on every AMP. This is true for both the USI and the NUSI. Subtables require additional disk space and maintenance; they should be only used on queries that run again and again.
The purpose of creating subtable is to point back to the real row in the base table via the Row-ID.
Before proceeding with the Secondary Index, it is recommended to learn about Primary Index in Teradata.
Now you have learnt about the primary index which provides fastest path to access data and avoid full table scan.Then why we want to define secondary index in a table?
As we know that we can define one and only one primary index for any specific table and accessing that table will be lightning fast only if we use primary index column(s) in where clause. But what if we access the table with some other column in where clause? In this case it will go for full table scan and some alternative thinking comes in mind.
Key points regarding Secondary Index:-
- We can define up to 32 secondary index.
- A Secondary Index has a limit of 64 columns.
- Teradata maintains separate subtable for each secondary index.
- Can be defined/dropped dynamically.
Unique Secondary Index (USI)
As the name suggest, USI enforces uniqueness on a column or group of column values. Teradata will create subtable on each amp once you create the USI on a column or group of columns. The subtable will contain below three information:-
- The secondary index value
- The secondary index row id
- The base table row ID
Syntax for creating USI:-
CREATE UNIQUE INDEX (column_name) on dbname.tablename;
Creation of subtable:-
Consider the below student table as an example for the better understanding:- 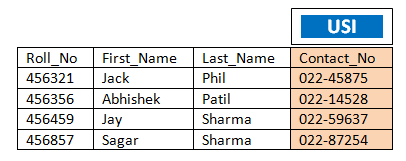 Suppose we have one table called student having four columns Roll_No, First_Name, Last_Name, Contact_No. Roll_No column has been defined as Primary index. So table will be distributed as per Roll_No across the AMP.
Suppose we have one table called student having four columns Roll_No, First_Name, Last_Name, Contact_No. Roll_No column has been defined as Primary index. So table will be distributed as per Roll_No across the AMP.
Now you have defined unique secondary index on the column Contact_No as below:
CREATE UNIQUE INDEX (Contact_No) on Mydb.student;
Teradata will perform below steps to maintain USI:
- As soon as you define USI, Teradata will create subtable for Contact_no on each AMP.
- Values from the USI column (in this case Contact_No) will be picked one by one and send to PE for hashing.
- After hashing the value using hash algorithm and hash map, it will find the destination amp for any particular value.
- In the destination AMP, index value will be stored along with the secondary index row-id and base row-id.
In this way Teradata create and maintain subtable. As USI column contains only unique values, no duplicate value is there in any subtable i.e. when you submit any query using USI, only one unique row will be returned.
USI Access:-
Now I am going explain if you submit any USI query, how it’s going to process and many AMP will involve and why? Its universal true that accessing data using USI is always 2 AMP operations. You will get to know little bit later. 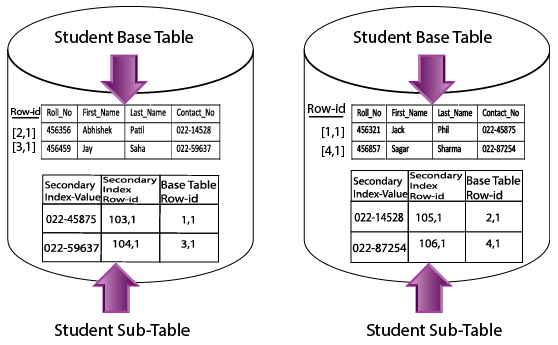 Suppose you have the below USI query-
Suppose you have the below USI query-
SELECT * FROM mydb.student where Contact_No = 022-45875;
Once the above query passes all the syntax and security check and Teradata optimizer finds that column associated with the where clause is an USI column, Teradata will fetch the record as below-
- Hashing algorithm hashes the USI value i.e. 022-45875 and generates hash value.
- Using hash map, it will find the amp number where the SI value is stored.
- Now it will go to the employee subtable and fetch the row-id of the employee base table.
- Once the row-id is received it will fetch for amp number where the base table row resides using Hash map.
- Thus the row is now found from the base table.
From the above steps it is now clear that retrieving data using USI is a always 2 AMPS operation and return single row only. First AMP is used to fetch the base row-id from the subtable and second amp is for the actual value from the base table.
Non-Unique Secondary Index (NUSI)
A Non-Unique Secondary Index(NUSI) is designed to prevent the full table scan(FTS) and usually contains duplicate values.
Once you create a secondary index, a subtable is created on each AMP.
The main difference between the USI and NUSI is that USI subtable rows are hashed and the NUSI subtable rows are AMP-Local. But why NUSI is AMP Local and what does it mean?
It is obvious that NUSI value is duplicate and there could be huge number of duplicate values in it. So Teradata takes a different strategy to maintain subtable in this case. Each row of the subtable only tracks the base rows on the same AMP. This is what is meant by AMP Local.
Syntax for creating USI:-
CREATE INDEX (column_name) on dbname.tablename; 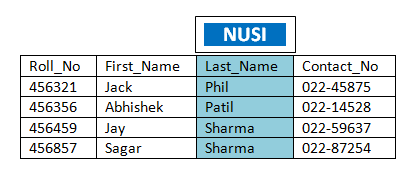 Now we have learnt that NUSI value is not used HASH MAP to find it destination AMP. Once you define Last_Name as a NUSI, Teradata will hash the Last_Name value and stores the row-id along with the index value in the subtable of same AMP. So NUSI subtable is AMP local. Another difference is that only one subtable row is maintained although there may be multiple row for a NUSI value in the same AMP. In this multiple base row-id will be maintained in a single row.
Now we have learnt that NUSI value is not used HASH MAP to find it destination AMP. Once you define Last_Name as a NUSI, Teradata will hash the Last_Name value and stores the row-id along with the index value in the subtable of same AMP. So NUSI subtable is AMP local. Another difference is that only one subtable row is maintained although there may be multiple row for a NUSI value in the same AMP. In this multiple base row-id will be maintained in a single row.
Data retrieval using NUSI:-
Consider the below query-
SELECT * FROM mydb.student where Last_Name = ‘Sharma’;
- Once Parsing Engine finds that Last_Name is defined as NUSI, it uses the hashing algorithm to generate the hash value which is circulated to all AMP. (In our case NUSI value is Sharma)
- Each Amp now start to match the hash value in their student subtable.
- AMP which does not have this hash value will not participate in this operation anymore.
- Other participating AMPs find the base row-id in their student and actual rows are fetched from the base table and returned back to the client.