Primary Index is the physical mechanism for storing and retrieving data row in Teradata AMP. Each table in Teradata must have at least one column as Primary Index. It is defined at the time of creating table. If any change in Primary Index needs to be implemented, one needs to drop the table and recreate it. PI can’t be altered or modified.
It is the most preferred and important index for below reasons:
- Data Distribution
- Known access path
- Improves Join performance
There are two types of Primary Indexes:
- Unique Primary Index (UPI).
- Non-Unique Primary Index(NUPI)
Let us now understand what exactly happens when you define a PI on the table.
Unique Primary Index(UPI):-
As the name suggests a UPI allows unique values i.e. no duplicates are allowed. It is a one AMP operation and data distribution is even. It can contain one null value.
Unique Primary Index Syntax:-
CREATE TABLE sample_1
(col_a INT,
col_b VARCHAR(20),
col_c CHAR(4))
UNIQUE PRIMARY INDEX (col_a);
For eg: We have an Employee table where EMP_NO is the primary index (we have chosen this as EMP_NO is unique to all).
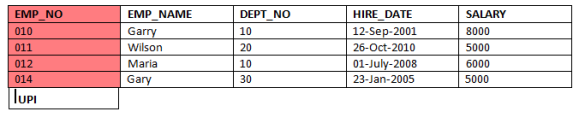 Data Distribution using UPI:-
Data Distribution using UPI:-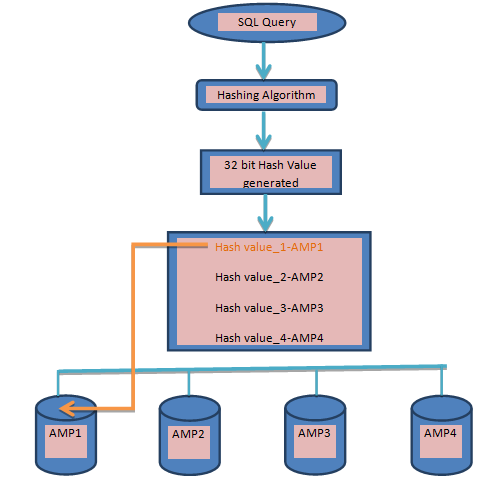 Sample query:-
Sample query:-
INSERT INTO DBNAME.EMPLOYEE VALUES (011,'Wilson',20,'2010-10-26',5000);
When a user submits an insert query for a table with Primary Index the following processes occur:
- The index value goes through a hashing algorithm and gives out a 32-bit Row-hash value something like this 0011 0011 0101 0101 0000 0001 0110 0001 for EMP_NO 011.
- The First 20 bit of this 32 bit Row hash value determines the AMP on which the row will reside. This is decided from the Hash map which contains 1 million hash bucket. Hash map looks something like this for 4 AMP system.
 So now the hash value will point to the particular amp from HASH MAP. e.g : Our value 0011 0101 0101 0000 0001 0110 0001 points to 2nd row , 1st column i.e. AMP 3. Now we have AMP 3 where the row will reside.
So now the hash value will point to the particular amp from HASH MAP. e.g : Our value 0011 0101 0101 0000 0001 0110 0001 points to 2nd row , 1st column i.e. AMP 3. Now we have AMP 3 where the row will reside.- The PE will send the row to the AMP with the hash value attached to it, something like this:
 A uniqueness value is defined for each row. As EMP_NO is unique to all, in the case of UPI the uniqueness value will be 1 for all. This can be well understood while we will study NUPI. So, this is how the row can be distributed to the AMP. The same is the process for retrieval.
A uniqueness value is defined for each row. As EMP_NO is unique to all, in the case of UPI the uniqueness value will be 1 for all. This can be well understood while we will study NUPI. So, this is how the row can be distributed to the AMP. The same is the process for retrieval.
Non-Unique Primary Index(NUPI):-
A NUPI can allow duplicates. It can have n number of null values.
Syntax for NUPI:-
CREATE TABLE sample_1
(col_a INT,
col_b VARCHAR(20),
col_c CHAR(4))
PRIMARY INDEX (col_a);
We will take the same example for understanding NUPI. 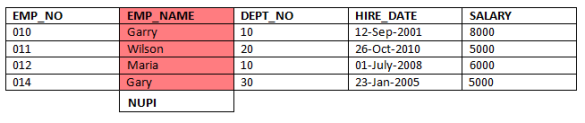 We have taken EMP_NAME as the NUPI column, as it can contain duplicate records. As per our table the employee name Gary has appeared twice which means it is a duplicate value. Now let us see what happens when PE receives a duplicate value.
We have taken EMP_NAME as the NUPI column, as it can contain duplicate records. As per our table the employee name Gary has appeared twice which means it is a duplicate value. Now let us see what happens when PE receives a duplicate value.
- The same process of generating the Row-Hash value is followed.
- To differentiate within the duplicates a uniqueness value is added with the hash-value, something like below:
 The uniqueness value is added to make the row unique from all the duplicates. If we had one more employee as Gary, the uniqueness value would have been 3 for him.
The uniqueness value is added to make the row unique from all the duplicates. If we had one more employee as Gary, the uniqueness value would have been 3 for him.- As the AMP is selected with the help of Hash value, all the duplicates value will go the same AMP.

- The duplicates reside on the same AMP, thus it leads to uneven distribution of data and may cause performance to degrade.
Also Read:-
1 thought on “Primary Index in Teradata”